
Sampling data or approximating probabilistic densities is one of the core problems in modern statistics, especially in Bayesian statistic. Beside of MCMC, Variational Inference is one of the two typical Bayesian approaches solving this problem. It leverages the Variational Inference algorithm to develop many recent powerful methods and models: Stochastic Variational Inference, Variational Autoencoder… This article briefly introduces Variational Inference algorithm.
The main ideas of Variational Inference (VI) is approximating the posterior with simpler variational distribution by solving optimization problem. The section 1 reviews Bayesian inference and latent variables. Section 2 presents objective of the algorithm and why it solves optimization problem. Section 3 shows some important mathematical contributions while attempting the target. Section 4 introduces Stochastic Variational Inference and finally the summary is presented.
1. Bayesian Inference and Latent variables
- Bayesian Inference
Bayesian inference supposes the probability of observations 
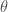
Prior:

Given 
Likelihood:

We don’t always know exact values of prior. Therefore, we have the hypothesis reflecting how much 
Posterior:

To test which parameters is best in describing the data, methods find which one has the maximum value of the likelihood or the posterior. If you’re not familiar with Bayesian inference, please read this post.
- Latent variables
In statistics, latent variables are variables that are not directly observed but are rather inferred (through a mathematical model) from other variables that are observed (directly measured). Mathematical models that aim to explain observed variables in terms of latent variables are called latent variable models.
See Wikipedia
Latent variables are not directly observed but we have information about their structure and relationship to the observations. Thus, it can be inferred. In Bayesian inference, they are often factors that allow us to factorize the observations to tractable distributions.
For example, in topic models, the only observation variable is collections of documents with their words. The list of topics, the distribution between topics and documents or words, both of them are latent variables.
2. Model’s objective and optimization problem
Variational Inference strives to sample observations or difficult-to-compute distribution. It uses hidden variables to encode hidden structure in observed data and estimates the posterior. The posterior is not always tractable, therefore, more generic way is approximating it by simpler distribution governed by variational parameters.
Goal distribution: the posterior

Approximating distribution: the variational distribution 
where 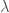
Loss function: the negative log likelihood

VI measures the distance between distributions by KL divergence:

Lower distance means better approximation, thus VI minimizes the distance and the problem becomes finding parameters which have optimal values on the targeting metric.
Instead of directly minimizing 



3. Mathematical notes
This section explains in detail mathematical points and how VI solves optimization problems.
3.1 Evidence Lower Bound (ELBO)
This term is called ELBO since it is the lower bound of evidence function of data:
![log p(x)= log \int p(x,z) dz = log \int \dfrac{p(x,z)q(z;\lambda)}{q(z; \lambda)} dz = log E_{q(z;\lambda)}\bigg[\dfrac{p(x,z)}{q(z; \lambda)} \bigg]](https://s0.wp.com/latex.php?latex=log+p%28x%29%3D+log+%5Cint+p%28x%2Cz%29+dz+%3D+log+%5Cint+%5Cdfrac%7Bp%28x%2Cz%29q%28z%3B%5Clambda%29%7D%7Bq%28z%3B+%5Clambda%29%7D+dz+%3D+log+E_%7Bq%28z%3B%5Clambda%29%7D%5Cbigg%5B%5Cdfrac%7Bp%28x%2Cz%29%7D%7Bq%28z%3B+%5Clambda%29%7D+%5Cbigg%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\geq E_{q(z;\lambda)}\bigg[log \dfrac{p(x,z)}{q(z; \lambda)} \bigg] = ELBO(\lambda)](https://s0.wp.com/latex.php?latex=%5Cgeq+E_%7Bq%28z%3B%5Clambda%29%7D%5Cbigg%5Blog+%5Cdfrac%7Bp%28x%2Cz%29%7D%7Bq%28z%3B+%5Clambda%29%7D+%5Cbigg%5D+%3D+ELBO%28%5Clambda%29&bg=ffffff&fg=404040&s=0&c=20201002)
Proof of 
3.2 Mean-field variational inference
To express

Due to this assumption, VI updates iteratively by pairs 
while (ELBO has not convergenced)
compute ELBO (q)
for j in {1, .. m}:
q_j(z_j) = q_j*(z_j) # optimal value of q_j(z_j)
Coordinate descent finds the steepest values of each variable while keeping others fixed, then updates the steepest to the variable. In contrast, gradient descent optimizes the whole dimensions at the same time, but with a small ratio of magnitude rather than full length of distant from current points to optimal values. Each time updating all factors, despite independently or simultaneously, the lower bound (ELBO) is increased, the training process found the better local optimum.
Both gradient descent or coordinate descent work by finding steepest values of local convex loss function. How to find them?
3.3 Natural gradient
The important thing to optimize the loss function
- Natural gradient and Fisher Information
Natural gradient is proven to be extracted by the equation:
where 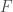

The Fisher Information matrix is computed by getting second-order gradient, Hessian matrix, of the
Let 


![F_\theta := E_\theta \bigg[ \nabla_\theta log (p_\theta(x)) \nabla_\theta log(p_\theta(x))^T \bigg] = -E_\theta \bigg[ \nabla_\theta^2 log(p_\theta(x)) \bigg]](https://s0.wp.com/latex.php?latex=F_%5Ctheta+%3A%3D+E_%5Ctheta+%5Cbigg%5B+%5Cnabla_%5Ctheta+log+%28p_%5Ctheta%28x%29%29+%5Cnabla_%5Ctheta+log%28p_%5Ctheta%28x%29%29%5ET+%5Cbigg%5D+%3D+-E_%5Ctheta+%5Cbigg%5B+%5Cnabla_%5Ctheta%5E2+log%28p_%5Ctheta%28x%29%29+%5Cbigg%5D&bg=ffffff&fg=404040&s=0&c=20201002)
- Proof

Suppose that 

![D_{KL}\bigg( p(x|\lambda^*) || p(x|\lambda) \bigg) = E_{p(x|\lambda)}\big[ log (p(x|\lambda^* )\big) \big] - E_{p(x|\lambda)}\big[ log (p(x|\lambda )\big) \big]](https://s0.wp.com/latex.php?latex=D_%7BKL%7D%5Cbigg%28+p%28x%7C%5Clambda%5E%2A%29+%7C%7C+p%28x%7C%5Clambda%29+%5Cbigg%29+%3D++E_%7Bp%28x%7C%5Clambda%29%7D%5Cbig%5B+log+%28p%28x%7C%5Clambda%5E%2A+%29%5Cbig%29+%5Cbig%5D+-+E_%7Bp%28x%7C%5Clambda%29%7D%5Cbig%5B+log+%28p%28x%7C%5Clambda+%29%5Cbig%29+%5Cbig%5D&bg=ffffff&fg=404040&s=0&c=20201002)
![\nabla_\lambda^1 D_{KL}\bigg( p(x|\lambda^*) || p(x|\lambda) \bigg) = \nabla_\lambda^1 E_{p(x|\lambda)}\big[ log (p(x|\lambda^* )\big) \big] - \nabla_\lambda^1 E_{p(x|\lambda)}\big[ log (p(x|\lambda)\big) \big]](https://s0.wp.com/latex.php?latex=%5Cnabla_%5Clambda%5E1+D_%7BKL%7D%5Cbigg%28+p%28x%7C%5Clambda%5E%2A%29+%7C%7C+p%28x%7C%5Clambda%29+%5Cbigg%29+%3D+%5Cnabla_%5Clambda%5E1+E_%7Bp%28x%7C%5Clambda%29%7D%5Cbig%5B+log+%28p%28x%7C%5Clambda%5E%2A+%29%5Cbig%29+%5Cbig%5D+-+%5Cnabla_%5Clambda%5E1+E_%7Bp%28x%7C%5Clambda%29%7D%5Cbig%5B+log+%28p%28x%7C%5Clambda%29%5Cbig%29+%5Cbig%5D+&bg=ffffff&fg=404040&s=0&c=20201002)
![= - E_{p(x|\lambda)}\big[\nabla_\lambda^1 log (p(x|\lambda )\big) \big]](https://s0.wp.com/latex.php?latex=%3D+-+E_%7Bp%28x%7C%5Clambda%29%7D%5Cbig%5B%5Cnabla_%5Clambda%5E1+log+%28p%28x%7C%5Clambda+%29%5Cbig%29+%5Cbig%5D+&bg=ffffff&fg=404040&s=0&c=20201002)
![\nabla_\lambda^2 D_{KL}\bigg( p(x|\lambda^*) || p(x|\lambda) \bigg) = - E_{p(x|\lambda)}\big[\nabla_\lambda^2 log (p(x|\lambda)\big) \big] = - \int p(x|\lambda) \nabla_\lambda^2 log (p(x|\lambda)\big) dx](https://s0.wp.com/latex.php?latex=%5Cnabla_%5Clambda%5E2+D_%7BKL%7D%5Cbigg%28+p%28x%7C%5Clambda%5E%2A%29+%7C%7C+p%28x%7C%5Clambda%29+%5Cbigg%29+%3D+-+E_%7Bp%28x%7C%5Clambda%29%7D%5Cbig%5B%5Cnabla_%5Clambda%5E2+log+%28p%28x%7C%5Clambda%29%5Cbig%29+%5Cbig%5D+%3D+-+%5Cint+p%28x%7C%5Clambda%29+%5Cnabla_%5Clambda%5E2+log+%28p%28x%7C%5Clambda%29%5Cbig%29+dx&bg=ffffff&fg=404040&s=0&c=20201002)
Evaluate

![= -E_{p(x|\lambda^*)}\bigg[ \nabla_\lambda^2 log (p(x|\lambda^*)\big) \bigg]](https://s0.wp.com/latex.php?latex=%3D+-E_%7Bp%28x%7C%5Clambda%5E%2A%29%7D%5Cbigg%5B+%5Cnabla_%5Clambda%5E2+log+%28p%28x%7C%5Clambda%5E%2A%29%5Cbig%29+%5Cbigg%5D&bg=ffffff&fg=404040&s=0&c=20201002)
Thus,

- Finding steepest points
Let 


With second-order Taylor Series:

Let 



To find 


Let 



The term
More detail in explaining natural gradient descent, check out here.
4. Stochastic Variational Inference (SVI)
SVI was inspired by Stochastic Gradient Descent, which separates the training set into many sub-set and feeds data to neural network with smaller size. This is helpful to save resource usage so that SVI is highly scalable while traditional method could fail to be trained because of loading full size of data. The challange of SVI is how to approximate the natural gradients of full data by natural gradients of small sub-set. They introduce global and local parameters for all hidden variables, including all latent variables and all their parameters. The global holds natural gradients of full dataset, while the local saves natural gradients of current sub-set.
Summary
Variational Inference methods use hidden variables to encode hidden structure in observed data. The relationship between the hidden variables and observations is factorized by joint probability distribution. Therefore, to sample observations, we estimate the posterior distribution (the conditional distribution of the hidden structure given the observations). This posterior could be not tractable to compute and we must appeal to approximate methods, thus approximating problem becomes optimization problem.
While dealing with the optimization task, KL divergence is used as a distance metric. But we do not minimize it. Instead, ELBO, which has close relation to KL divergence, provides an easier way to reach global optimum by iteratively increasing the lower bound. This step is done by coordinate descent or gradient descent to find the steepest points of factors.
Another important theorem is mean-field variational inference. It allows approximating complicated structure of distributions and also is easier to track. Then each factor can be updated independently by steepest descent algorithms.
These algorithms are difficult to find optimal points without assisting of the natural gradient since parameters are in Euclidean space while distance metric is in distribution space. Fisher information matrix, a transformation between two kinds of space, is a key contribution of natural gradient.
Finally, Stochastic Variational Inference inherits ideas of Stochastic Gradient Descent and proposes terms of global and local parameters. They respectively hold full-batch gradients and mini-batch gradients of models. SVI achieves in improving the scalability of methods, making Variational Inference methods more wide-known today.

Chào An,
Lâu rồi không thấy An viết blog lại. Nếu An đọc được những dòng này, mong em sẽ có thật nhiều sức khoẻ và một tâm hồn an lạc như chính tên em.
Thân ái,
Duy.
LikeLiked by 1 person