
Convolutional Neural Network brings several breakthroughs for supervised tasks in Computer Vision and other visual problems in Artificial Intelligence. Moreover, semi-supervised or unsupervised learning has remarkable milestones in attempts to understand how models work. These insights unfold impressive studies which utilitize pre-trained models to extract deep-learning-based features or solve various tasks.
This post introduces Artistic Style Transfer with Neural Algorithm as the typical method in such success. First, solving the object recognition problem with Convolutional Neural Network is presented, then Section 2 provides explanations of how it works by visualizing the pre-trained model. And the final is applying to reconstruct style and content of images. In addition, throughout sections, some experiments with PyTorch code are included.
1. Object Recognition with Convolutional Neural Network
1.1 Object Recognition
Object recognition is a typical task in Artificial Intelligence. Supporting a wide range of applications but facing many challenges, there are a huge number of studies contributing to discovery of this topic. In academy, to officially validate the performance of methods, there is an online competition, called Image Classification with ImageNet dataset. It provides large collection of pictures and their labels, includes various kinds of objects: animal, plant, scene, instrumentation, etc. From 2010, there are a few winning models with different architectures and strategies. All of them are Convolutional Neural Network.
Opening deep learning frameworks such as Keras, Pytorch, prepare access to not only this dataset but also pre-trained CNN models.
1.2 Convolutional Neural Network
Convolutional Neural Network is a popular deep learning model applied commonly in visual tasks. It is inspired by biological processes in the visual cortex of cats. There are two mechanisms: globally observing and locally focusing, which correspond to pooling and convolution operator. The name of this model indicates that it performs this mathematical operation.
Convolutional Neural Network includes several blocks. Each block contains 3 components: convolutions, non-linear activation function and pooling. Convolutions employ convolution operators between small areas of given data and k filters in parallel, produce k images simultaneously. Using the same input, the values of these images depend on values of filters. They are computed by training with labels in particular tasks. Next, the common activation function in CNN is ReLU. Finally, pooling summarizes local information of adjacent positions and generates the outputs with smaller size. For example, it gets the maximum of 2×2 regions so that the image size reduces 2 times in height and 2 times in width.
After convolution blocks is the fully connected layer. The last layer is soft-max function, which normalizes all values to approximate probabilities of object labels.

For more detail in Convolution Neural Network, please read this article.
1.3 Visualization of CNN models in object recognition task
Deep learning models are reputed as black box, means we know the inputs, the labels, the weights learned as outcomes, but we have no idea how to explain the results. Fortunately, previous studies discovered ways visualizing CNN models, which help us in understanding and leveraging them better. Some simply show values of filters as images with short discussion, like relationship between filters or their values. Others visualize results of convolution operators between the input image and filters.
These figures below illustrates visualization of some filters of AlexNet and VGG19 and their results when feeding the input (figure 1.2).

Structure of VGG19:
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
Visualization for VGG19 is in figure 1.3 and figure 1.4. Its first layer has 64 filters. The 7th layer has 128 filters.




Visualization for AlexNet is in figure 1.5. Its first layer has 64 filters.


In PyTorch, it is very easy to access values of weights as well as their outputs. The script below shows how to load an image, models and extract these values in order to visualize models.
import torch
import torchvision
import torchvision.models as models
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
'''read image as numpy matrix with shape (72, 72, 3)'''
datapath='maru.jpg'
np_img = mpimg.imread(datapath)
'''convert image from numpy to tensor with correct shape.
Tensor has shape (batch, channel, height, width)'''
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
tensor_img = transform(np_img).float().resize_(1, 3, 72, 72)
'''load pre-trained models'''
vgg19 = models.vgg19(pretrained=True) #load VGG19
alexnet = models.alexnet(pretrained=True) #load AlexNet
'''access layers and outputs of pre-train models'''
seq = vgg19.features #type: torch.nn.Sequential()
weight_layer0 = seq[0].weight.data
weight_layer10 = seq[10].weight.data
output_layer0 = seq[0](tensor_img)
output_layer10 = seq[0:11](tensor_img)
output_final = seq(tensor_img)
2. Neural Algorithm of Artistic Style
The algorithm leverages models pre-trained with the image classification task. It does not use the classifying step, but just weights of inner layers that transform inputs to probabilities of classes. It figures out information representing objects of images. Furthermore, it extracts abstract style rather than visual features such as contrast, color, edges, etc, comparing to previous studies. That means the authors do not need to deal with challenges when conveying and fusing such meaningful information to computers. Instead, models could directly work with features. Then, the article shows how to reconstruct individually the content and style of images and even re-combine them. To prove this ability, the authors conducted experiments that re-drawn images with artistic style from famous paintings in art, called style transfer.
2.1 Extract features of Content and Style
- Content Extractor
After training with the classification task, CNN models can recognize objects in images. Due to their success in dealing with a wide range variation of object representation, pre-trained models are able to distinguish which information is related to objects or not. Some previous works also present methods that visualize which pixels or features have significant impacts on recognition results. Thus, it is appropriate to think that information of content is existed and can be captured as features from pre-trained models. According to the authors, it is the set of results of convolution layers. By experiments, they selected the second convolution layer of the forth block (conv4_2) to represent content of images.
To implement, I define a content extractor, inheriting nn.Module class of PyTorch. Check this link to see how to custom nn.Module. Follow the description above, here is Content_Extractor class:
class Content_Extractor(torch.nn.Module):
def __init__(self, model):
super(Content_Extractor, self).__init__()
self.model = model
self.layers=[21] #[21] #conv4_2
def forward(self, x):
return [self.model.features[0:i+1](x) for i in self.layers]
content_extractor = Content_Extractor(vgg19) # a Content_Extractor instance
In forward function, computing values of low-level layers over and over makes the time cost high. I adjust this by calculating the current layer from previous results as the script below:
def forward(self, x):
# return [self.model.features[0:i+1](x) for i in self.layers]
if len(self.layers) == 0:
return []
prev_layer = self.layers[0]
content = [self.model.features[0:self.layers[0]+1](x)]
for i in self.layers[1:]:
content.append(self.model.features[prev_layer+1:i+1](content[-1]))
prev_layer = i
return content
- Style Extractor
The authors suppose that style is constant with different filters in a layer. That is to say, how an image is drawn is global information like the content. Suffering different convolution filters, the image is transformed but still keeps the style consistent in different responses of a layer. Thus, obtaining style is achieved by getting correlation between them. The correlation is given by Gram matrix 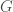

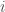

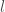

By experiments, the authors selected the the first convolution layer of each block (conv1_1, conv2_1, conv3_1, conv4_1, conv5_1) to represent style of images.
def gram_matrix(feature_map):
n_channel, n_filter, w, h = feature_map.shape
features = feature_map.view(n_channel * n_filter, w * h)
G = torch.mm(features, features.t())
return G.div(n_channel * n_filter * w * h)
class Style_Extractor(torch.nn.Module):
def __init__(self, model):
super(Style_Extractor, self).__init__()
self.model = model
self.layers= [0, 5, 10, 19, 28] #conv1_1, conv2_1, conv3_1, conv4_1, conv5_1
def forward(self, x):
# return [gram_matrix(self.model.features[0:i+1](x)) for i in self.layers]
if len(self.layers) == 0:
return []
prev_layer = self.layers[0]
cnn_layers = [self.model.features[0:self.layers[0]+1](x)]
for i in self.layers[1:]:
cnn_layers.append(self.model.features[prev_layer+1:i+1](cnn_layers[-1]))
prev_layer = i
style = []
for i in range(len(cnn_layers)):
style.append(gram_matrix(cnn_layers[i]))
return style
2.2 Loss of reconstruction
- Content and Style reconstruction
To reconstruct content or style of an image, we start with a random image. Let say representation of original image and random image respectively are 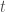





This is also called mean square error (MSE) between 



Reconstructing style or content becomes minimizing the total loss. It can be done normally by gradient descent algorithms.
Here I define the loss of reconstruction as a class in PyTorch:
class Reconstruction_Loss(torch.nn.Module):
def __init__(self, extractor, target_img):
super(Reconstruction_Loss, self).__init__()
self.extractor = extractor
target_tensor = target_img
self.target = [l.detach() for l in self.extractor(target_tensor)]
def forward(self, x):
F = self.extractor(x)
loss_list =[torch.nn.functional.mse_loss(F[l], self.target[l]) \
for l in range(len(self.extractor.layers))]
total_loss=0
for loss in loss_list:
total_loss += loss
return total_loss
Use the class with Content_Extractor or Style_Extractor, we obtain a model to reconstruct content or style respectively. To train this model, I define a reconstruct function below. Check this link if you are not familiar with training PyTorch models.
def reconstruct(model, target, epochs):
img = torch.rand(target.shape).requires_grad_(True)
optimizer = torch.optim.Adam([img], lr=0.1)
for epoch in range(epochs):
img.data.clamp_(0, 1)
optimizer.zero_grad()
loss = model(img)
loss.backward()
optimizer.step()
if (epoch==0 or epoch % 100==99):
print ('Epoch %d: Loss=%.4f' % (epoch, loss))
img.data.clamp_(0, 1)
return img
Before running these code, we need
- prepare tensor variables for input images and results.
- turn off using gradients for pre-trained model.
- declare a content or style model by using Reconstruct_Loss and Content_Extractor or Style_Extractor.
def convert_tensortonp(tensor_img):
return np.stack([tensor_img.data[0, 0, :, :].numpy(), \
tensor_img.data[0, 1, :, :].numpy(), \
tensor_img.data[0, 2, :, :].numpy()], axis = 2)
def convert_totensorimg(np_img, requires_grad=False):
w, h, c = np_img.shape
tensor_img = torch.tensor(transform(np_img).float().resize_(1, c, w, h),\
dtype=torch.float32, requires_grad=requires_grad)
return tensor_img
import copy
vgg19 = copy.deepcopy(models.vgg19(pretrained=True))
for param in vgg19.parameters():
param.requires_grad_(False)
target_tensor = convert_totensorimg(maru_img, requires_grad=False).to(device)
model = Reconstruction_Loss(Content_Extractor(vgg19), target)
Finally, call the reconstruction and see what happen:

- Style Transfer
Similar to content and style reconstruction but not individually, style transfer strives to minimizing both of them simultaneously. The loss is sum with weights of content and style, where the ratio between content and style often is 
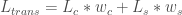
In implementation, I define a class Style_Transfer_Loss to compute this loss. As Reconstruction_Loss, it contains instance of Content_Extractor or Style_Extractor. Running each of them need visiting layers in vgg19 once. Instead of running the vgg19 twice in total, for content and style separately, I create a new model for Style_Transfer_Loss from the original by the function create_styletransfer_model.
Modify the original model:
- For short, create 2 objects: Content_Loss (from Content_Extractor and Reconstruction_Loss) and Style_Loss (from Style_Extractor and Reconstruction_Loss).
- Add instances of Content_Loss and Style_Loss objects after appropriate convolution layers.
- According to the article, changing pooling from max to average improves the gradient flows.
- Current ReLU function use inplace=True in their setting, which means assigning directly new values to current variables. Changing inplace=False lets the model create new variables to store new values, make better performance when computing gradients.
- Drop redundant layers.
from torch import nn
def create_styletransfer_model(self, content_tensor, style_tensor, \
content_layers, style_layers):
layer_cnt = 0
seq = nn.Sequential()
for layer in vgg19.features:
if isinstance(layer, nn.MaxPool2d):
layer = nn.AvgPool2d(kernel_size=2, stride=2)
elif isinstance(layer, nn.ReLU):
layer = nn.ReLU(inplace=False)
seq.add_module('{}'.format(layer_cnt), layer)
if isinstance(layer, nn.Conv2d):
if layer_cnt in content_layers:
target = vgg19.features[:layer_cnt+1](content_tensor).detach()
content_loss = Content_Loss(target)
seq.add_module("ContentLoss_{}".format(layer_cnt), content_loss)
self.content_loss_list.append(content_loss)
if layer_cnt in style_layers:
target = vgg19.features[:layer_cnt+1](style_tensor).detach()
style_loss = Style_Loss(target)
seq.add_module("StyleLoss_{}".format(layer_cnt), style_loss)
self.style_loss_list.append(style_loss)
layer_cnt +=1
if (len(content_layers)==0 or layer_cnt>content_layers[-1]) \
and (len(style_layers)==0 or layer_cnt>style_layers[-1]):
break
return seq
With configuration content_layer = [7] (conv2_2), style_layer=[0, 5, 10] (conv1_1, conv2_1, conv3_1), the model of Style_Transfer_Loss:
Style_Transfer_Loss(
(model): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(StyleLoss_0): Style_Loss()
(1): ReLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): AvgPool2d(kernel_size=2, stride=2, padding=0)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(StyleLoss_5): Style_Loss()
(6): ReLU()
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(ContentLoss_7): Content_Loss()
(8): ReLU()
(9): AvgPool2d(kernel_size=2, stride=2, padding=0)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(StyleLoss_10): Style_Loss()
)
)
Here is the detail of Style_Transfer_Loss.
CONFIG_CONTENT_LAYERS, CONFIG_STYLE_LAYER = [21], [0, 5, 10, 19, 28]
CONFIG_WEIGHT_STYLE = [0.2, 0.2, 0.2, 0.05, 0.35]
class Style_Transfer_Loss(nn.Module):
def __init__(self, content_tensor, style_tensor):
super(Style_Transfer_Loss, self).__init__()
#hyper-parameters
self.content_weight, self.style_weight = 1, 1e5
self.content_loss_list, self.style_loss_list = [], [], []
self.content_layers = CONFIG_CONTENT_LAYERS
self.style_layers = CONFIG_STYLE_LAYER
self.weight_style_list = CONFIG_WEIGHT_STYLE
#init
self.content_loss, self.style_loss = 1e8, 1e8
self.create_model = create_styletransfer_model
seq = self.create_model(self, content_tensor, style_tensor, \
self.content_layers, self.style_layers)
self.model = seq.to(device)
def forward(self, x):
L_content, L_style = 0, 0
self.model(x)
for l in self.content_loss_list:
L_content += l.loss
for i in range(len(self.style_loss_list)):
l = self.style_loss_list[i]
w = self.weight_style_list[i]
L_style += l.loss * w
self.content_loss = L_content * self.content_weight
self.style_loss = L_style * self.style_weight
self.loss = self.content_loss + self.style_loss
return self.loss
3. Experiements with Style Transfer
Let have some experiments with the photo of the village as the content, and two famous artistic paintings Rain Princess and Starry Night as style images. Outputs are expected as keeping the global object arrangement as the content but these objects are drawn by texture as the style, such as colorful and glossy pieces in the Rain Princess or blue waves in Starry Night.
- Size of content image
Size of input is a simple but important configuration parameter. With small enough value, we can both observe results and have fast running time. With high value, the effect of style is more detail and complex, but may take much longer time to complete the training step.

- Convolution Layer for Content and Style Configuration
Different layer contains different types of visual information of style. According to the paper and my experiences, low-level layers are related more to color, contrast; the middle could capture edges, movements of artists when drawing; high-level layers is more sophisticated, mixing previous information to form abstract features.
In some cases, the loss of convolution layers in block 4 is very high. Removing this imbalance can be achieved by keeping their weights small.

Setting with combination of configuration and running with full size of content image, images generated have more sophisticated patterns with smooth coloring and thick texture.


Other results for other content images (the left): using Rain Princess is the middle and the right is combining style of Starry Night.



